Being defensive about what you enqueue into Sidekiq

What happened?
At Fieldwire, Sidekiq is used for processing offline jobs: a floorplan needing OCR, an account billing, etc.
Since so much of our mission-critical workflow depends on Sidekiq, it is important for us to keep the Sidekiq queue size and latency within a normal range. Sidekiq jobs depend on Redis to store all its operational data. Therefore, recently, we were alarmed to see a spike in Redis memory usage.
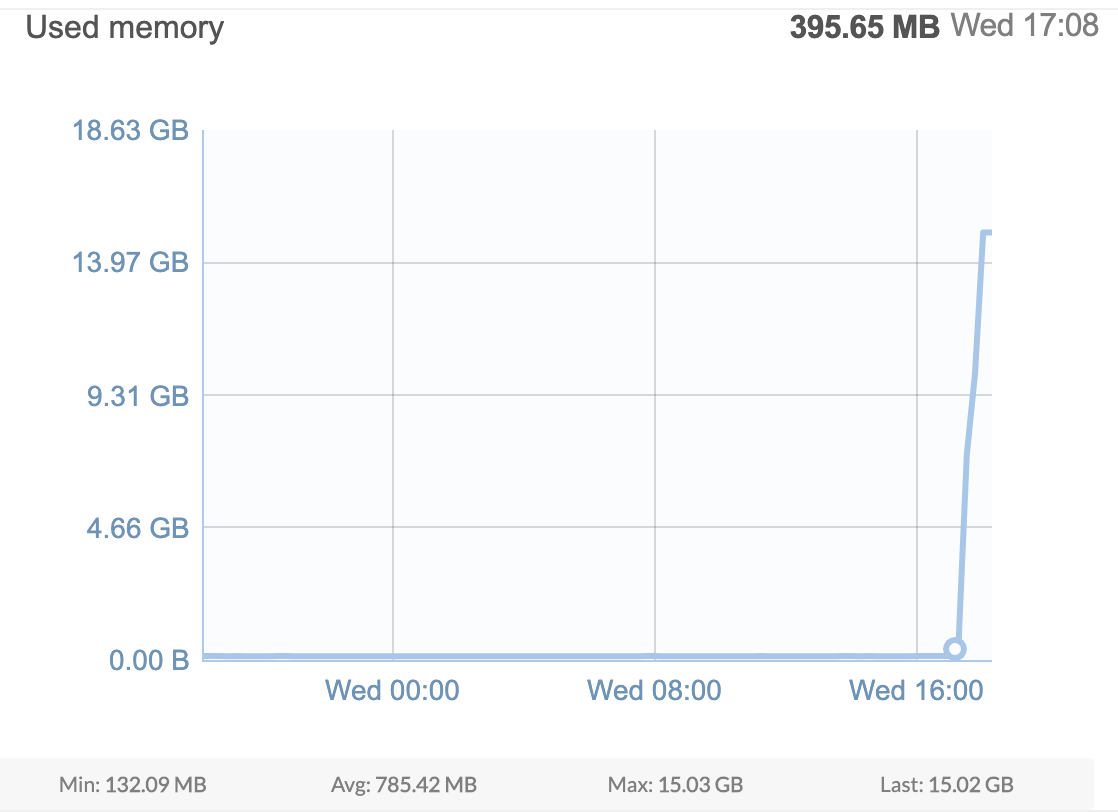
Because Redis was quickly running out of memory, the team swiftly responded. Not having sufficient memory would have meant that all other jobs would have been severely impacted.
What caused this?
By looking at the Sidekiq queue latency and size we were able to determine that the problem occurred between 9am and 10am. Better yet, it appeared that a single worker that was responsible for flattening image markups on our Task bubbles was at fault.
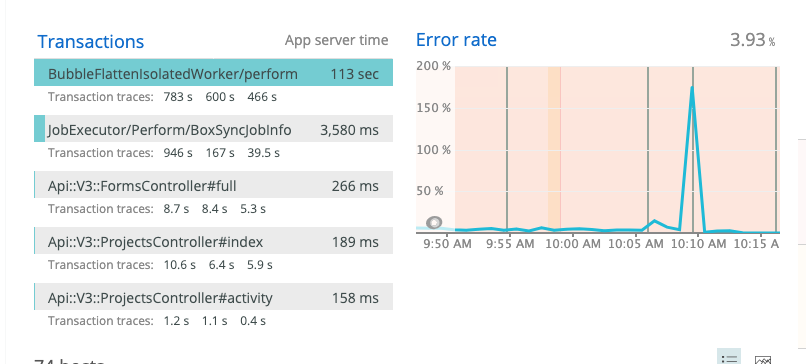
Let’s take a peek inside this worker.
class BubbleFlattenIsolatedWorker
...
def perform(bubble_id, bubble_file_url, bubble_active_markups_data_and_device_created_at)
...
Each of the markups in bubble_active_markups_data_and_device_created_at is actually a GeoJSON. For example, here is an Arrow:
{
"type": "Feature",
"properties": {
"style": "arrow",
"color": "#FF0000",
"opacity": 1,
"width": 16
},
"geometry": {
"type": "LineString",
"coordinates": [
[
136,
95
],
[
277,
17
]
]
}
}
Here is how a Fieldwire user is creating them:
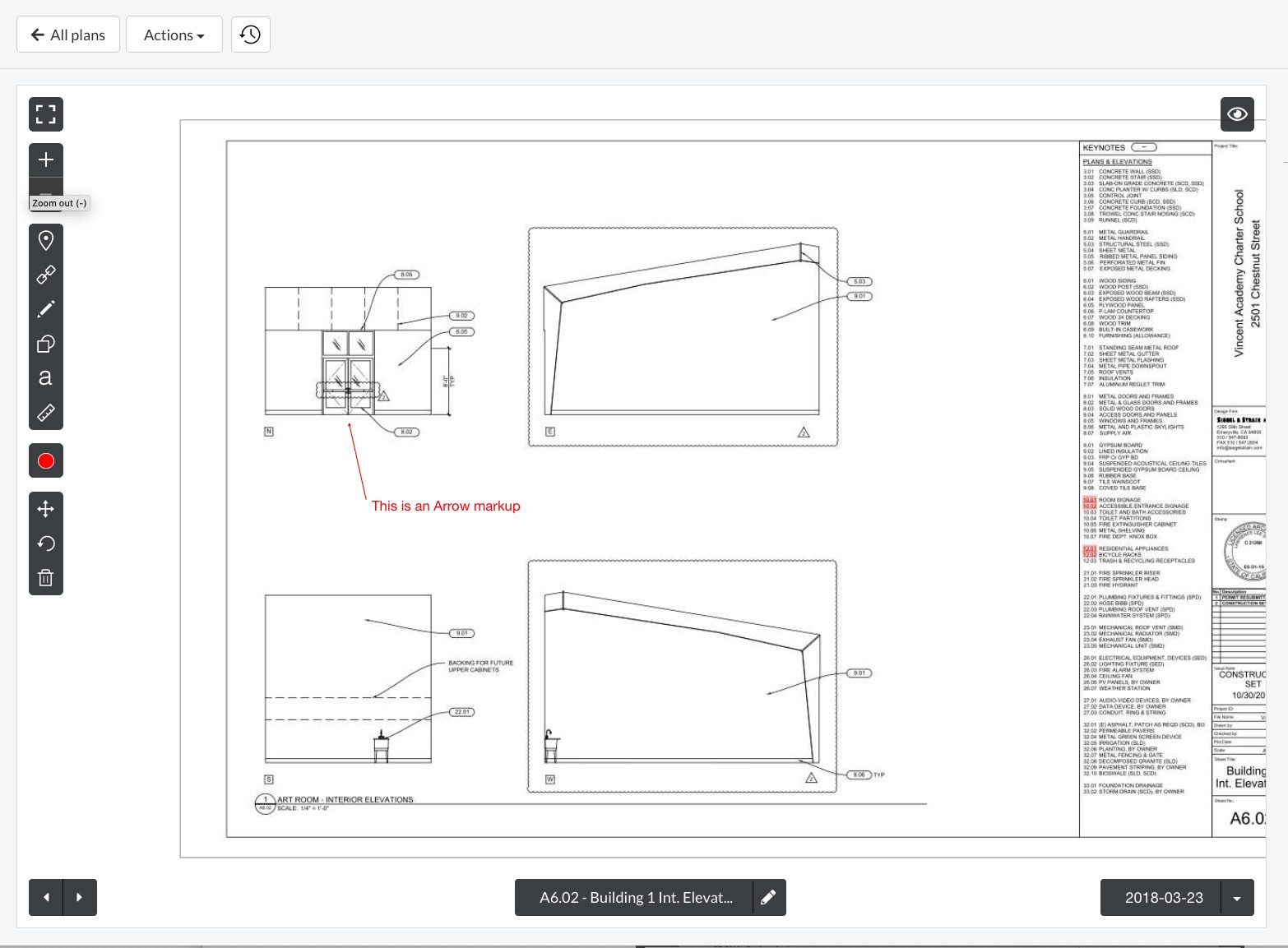
In this particular instance, however, a Fieldwire API client was erroneously drawing thousands of duplicate markups on a photo.
How can we prevent this from happening in the future?
Besides educating our API clients on correct usage, we also need to be defensive when responding to requests.
If we can detect the size of the arguments submitted to worker.perform(...) before they are enqueued and sent to Redis, we can prevent some workers from submitting enormous workloads.
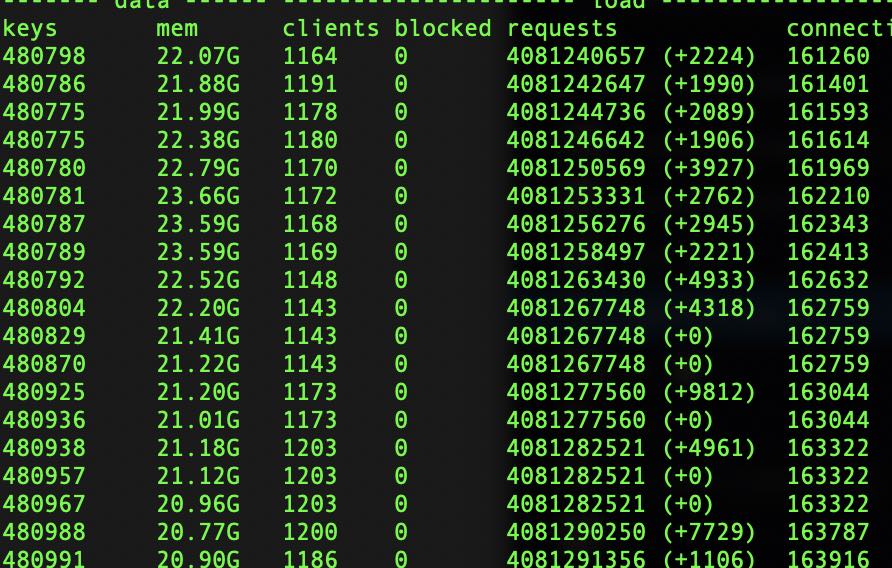
Utilizing the following command, we can view the large keys that were inside Redis during the incident:
redis-cli -u <substitute-redis-url-here> --bigkeys
Enter the JobMetrics Sidekiq client middleware
Using the Sidekiq client middleware, we can tap into a worker’s perform call and examine the current state of the queue and the worker’s arguments before it is enqueued. If a job’s argument size is larger than some upper bound we have chosen, we will discontinue the job and log out an error informing us of the violation.
First, in Rails, we add the JobMetrics middleware.
# in config/initializers/sidekiq.rb to add to the chain of client middleware
Sidekiq.configure_client do |config|
config.client_middleware do |chain|
chain.add Middleware::Sidekiq::Client::DisableJob
chain.add Middleware::Sidekiq::Metrics::Client::JobMetrics # <------ Here we add the ability to disable the job
chain.add Middleware::Sidekiq::Client::TraceJob
chain.add Middleware::Sidekiq::JobCount::Client::LogJobEnqueued
end
end
The JobMetrics middleware will look like this:
ARG_LIMIT = 1.megabytes
module Middleware
module Sidekiq
module Metrics
module Client
class JobMetrics
def call(worker_class, job, queue, redis_pool)
bytes = ObjectSpace.memsize_of(job['args'])
if bytes > ARG_LIMIT
Log.error('Sidekiq Job exceeded argument size limit. Job Disabled.')
return false
end
yield # yielding control back to middleware stack
end
end
end
end
end
However, we discovered an issue related to Ruby’s allocation of memory for objects. Specifically, for
Array, String, Struct, and Hash types, it uses the C implementation. Therefore, calling ObjectSpace.memsize_of(...) isn’t completely accurate since for Sidekiq it will serialize that data and store it on Redis.
# arrays
irb(main):031:0> ObjectSpace.memsize_of([])
=> 40
irb(main):032:0> ObjectSpace.memsize_of([1])
=> 40
irb(main):033:0> ObjectSpace.memsize_of([1,2,4])
=> 40
# strings
2.4.2 :062 > ObjectSpace.memsize_of("")
=> 40
2.4.2 :063 > ObjectSpace.memsize_of("a"*23)
=> 40
2.4.2 :064 > ObjectSpace.memsize_of("a"*24)
=> 65
# hashes
2.4.2 :044 > ObjectSpace.memsize_of({})
=> 40
2.4.2 :045 > ObjectSpace.memsize_of({a: 1})
=> 192
2.4.2 :046 > ObjectSpace.memsize_of({a: 1, b: 2, c: 3, d: 4})
=> 192
2.4.2 :047 > ObjectSpace.memsize_of({a: 1, b: 2, c: 3, d: 4, e: 5})
=> 288
In the end, we came up with a different way of computing a sufficient estimation of payload size:
- Push all arguments onto the stack for us to evaluate.
- Use simple constant sizes for booleans, numbers, and strings.
- For hashes and arrays look into each element by pushing them back onto our stack for evaluation.
- Continue adding until the stack is empty or we’ve hit a size limit.
module Metrics
def custom_byte_size(args)
# initialize the stack
stack = [].push(args)
total = 0
loop do
current = stack.pop
case current
when String
total += current.bytesize
when TrueClass
total += 1
when FalseClass
total += 1
when Integer
total += 4
when Float
total += 4
when Array
# add the additional 40 bytes for the Array object
total += 40
current.each do |x|
stack.push(x)
end
when Hash
# add the additional 40 bytes for the Hash object, each symbol character we add the size of the symbol
total += 40
current.map do |k, v|
total += k.size
stack.push(v)
end
else
total += 40 # other data types considered Ruby object and assign it 40 bytes
end
raise SizeExceeded.new('Sidekiq job argument size exceeded.', total) if total > ARG_LIMIT
break if stack.empty?
end
total
end
end
At first, we used a recursive algorithm but we encountered a stack overflow problem and didn’t have a short-circuit. We found the iterative approach worked well instead.
Changing our JobMetrics to use our custom logic for calculating argument size, plus adding in some safety feature flags and logging, we get:
ARG_LIMIT = 1.megabytes
module Middleware
module Sidekiq
module Metrics
module Client
class JobMetrics
def call(worker_class, job, queue, redis_pool)
begin
bytes = Metrics.byte_size_under_limit(job['args'])
rescue SizeExceeded => e
info = {
class: worker_class,
jid: job['jid'],
arg_size: e.human_friendly_size_string,
args: job['args'].to_s[0..100],
}
Log.error("Sidekiq Job disabled by JobMetrics middleware: #{worker_class}", e, info)
return false
end
yield
end
end
end
end
end
That is how we can prevent future workers from trying to enqueue large amounts of data into Redis!
Testing and safety
At Fieldwire we focus on quality. Measure twice, cut once. Developers are responsible for feature testing from development to staging to production. We also make extensive use of feature flags in our codebase for an added level of safety.
Observations in production
We performed some preliminary research on which workers could be the most problematic and added them to our WATCHLIST. We then monitored them for a few weeks to see the memory footprint of their argument size.
ProjectExportWorker
min 202 bytes
max 45400 bytes
avg 2042 bytes
BubbleFlattenIsolatedWorker
min 195.0 bytes
max 54100.0 bytes
avg 32683 bytes
FloorplanExportWorker
min 241.0 bytes
max 36200.0 bytes
avg 2521 bytes
SingleFormExportWorker
min 212.0 bytes
max 559.0 bytes
avg 282 bytes
SheetCirclesResultsWorker
0
FormTemplateGenerateWorker
min 112.0 bytes
max 6480.0 bytes
avg 1195 bytes
Alerting and maintainability
When we turned these features on, we also set up alerting through a Slack channel and email to notify us when a worker violates the Sidekiq argument size restriction. This gives us the opportunity to refactor troublesome workers and prevent them from initiating huge workloads.
With this JobMetrics middleware, we can be more defensive about what we enqueue into Sidekiq.